Why do we need an event model? Many RDF streaming systems discussed have little or no model for the real-time data they ingest. These systems make the lowest common assumptions about the structure of the data, i.e. that the data consist of a stream of RDF triples. Thus, each piece of real-time data (event) is one triple. One triple, however, cannot hold a lot of information. For example: flexibility in timstamping (one vs. two timestamps or application time vs. system time) is only possible if timstamps can be attached to event structure. Flat triples cannot do that. Another example is when typing data, the triple <myInstance> rdf:type <MyClass> can introduce a type, but the event (one triple) is "full". This means that any structure in the data must be inferred from more than one event. However, consumers cannot make assumptions about events which are not yet received: Events occur spontaneously and event consumers are often decoupled from the senders (cf. publish/subscribe systems). Therefore, structure is needed in individual events.
Events should be self-describing. A common understanding of data is crucial for consumers and producers , especially in a distributed and heterogeneous system such as the Web. Therefore, a consumer must find a way to understand received events which entails the need for a universal event model .
Model
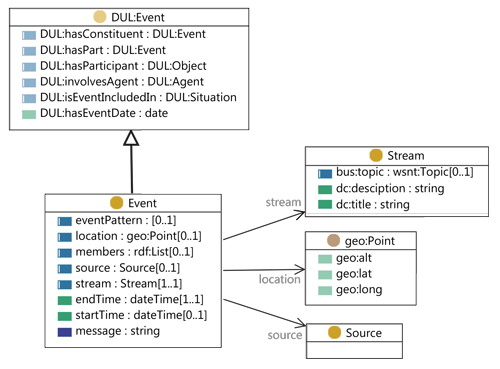
The figure shows the event model in a class diagram . The class "Event" at bottom left of the figure is the superclass for any event to conform to our model. This class makes use of related work by inheriting from the class "DUL:Event" from Dolce Ultralight based on DOLCE . That class provides a notion of time and helps distinguish events (things that happen) from facts (which are always valid).
")
In accordance with our requirements some properties are mandatory while the rest are optional. An instance of class Event MUST have (i) a type, (ii) at least one timestamp and (iii) a relevant stream. We describe the event properties in detail as follows.
The type of an event must be specified using rdf:type. The type must be the class Event or any subclass.
The event model supports interval-based events as well as point-based events by either using just the property :endTime for a point or both :startTime and :endTime for an interval. The property :endTime thus has a cardinality of [1..1] whereas :startTime has a cardinality of [0..1]. Both temporal properties are subproperties of DUL:hasEventDate from the super class. We improve the semantics by distinguishing start from end whereas the superclass has an alternative, more difficult way of formulating intervals using subobjects reifying the interval.
The property :stream associates an event with a stream. Streams are used in our system as a unit of organisation for events governing publish/subscribe and access control. Streams themselves are modelled using title, description and a topic needed for topic-based publish/subscribe.
The first optional property is :location. For for geo-referencing of events (where necessary) we re-use the basic geo vocabulary from the W3C . The property may be used to locate events in physical locations on the globe. The property is subproperty of DUL:hasLocation and geo:location to inherit the semantics from those schemas.
Inter-event relationships may be supported by linking a complex event to the simple events which caused it. Thus, RDF Lists may be used in :members to maintain an ordered and complete account of member events. The linked events are identified by their URI. These linked events could have further member events themselves. This facilitates modelling of composite events . The :members property is a subproperty of DUL:hasConstituent from the superclass.
The property :eventPattern may be used to link a complex event to the pattern which caused the event to be detected. Direct links to event patterns may be provided by RESTful services. Using such links can help in recording provenance of derived events.
The source of an event may be specified using the :source property. This is an optional property to record the creator of an event where needed. The property is a subproperty of DUL:involvesAgent. Agents may be human or non-human.
A human readable synopsis of an event may be added using the :message property. This proves useful in scenarios where events are received by human end users. The :message property is a subproperty of dc:title, a popular way of describing things using natural language. Multilingualism is provided by the feature of language tags for string literals in RDF .
N-ary predicates may be used to maintain event properties which are valid only for a specific event, e.g. a volatile sensor reading such as the temperature measurement belonging to a specific event. For example, instead of plainly stating the disputable fact that "the city of Nice has a temperature in Celsius of 23 degrees" which looks like this:
dbpedia:Nice :curTemp "23" .
We can instead state that the city of Nice has said temperature but qualified by the conjunction with a given event "e2" in the following n-ary predicate:
dbpedia:Nice :curTemp [
rdf:value "23" ;
:event <http://events...org/ids/e2#event>
] .
Endowment of further structure for events is left to domain-specific schemas. For example the W3C Semantic Sensor Network (SSN) Ontology may be added if fine-grained modelling of sensors and pertaining sensor readings is needed.
Example
The listing below shows several facts about our event model along an example. The listing uses the example of a Facebook event generated by our event adapter described in .
@prefix : <http://events.event-processing.org/types/> .
@prefix e: <http://events.event-processing.org/ids/> .
@prefix user: <http://graph.facebook.com/schema/user#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
e:5534987067802526 {
<http://events.event-processing.org/ids/5534987067802526#event>
a :FacebookStatusFeedEvent ;
:endTime "2012-03-28T06:04:26.522Z"^^xsd:dateTime ;
:status "I bought some JEANS this morning" ;
:stream <http://streams...org/ids/FacebookStatusFeed#stream> ;
user:id "100000058455726" ;
user:link <http://graph.facebook.com/roland.stuehmer#> ;
user:location "Karlsruhe, Germany" ;
user:name "Roland Stühmer" .
}
- The example shows an event using quadruples in TriG syntax . The graph name (a.k.a context) before the curly braces is used as a unique identifier, e.g. to enable efficient indexing of contiguous triples in the storage backend for historic events.
- The event in this example has the ID
5534987067802526 as part of its URI. There is a distinction made between URIs for things and URIs for their information resources, i.e. the event object 5534987067802526#event and the Web document 5534987067802526 describing the event. The two URIs might carry, e.g. a different creation date, which is why it can be important to separate them. The fragment identifier #event is used to differentiate them. See for an in-depth discussion of the matter of disambiguation (also known as the httpRange-14 issue).
- There is an event type hierarchy from which the type Facebook-StatusFeedEvent is inherited. This hierarchy can be extended by any user by referencing the RDF type
:Event as a super class.
- The event may link to entities from static Linked Data where further context for the event can be retrieved. In this example the event uses
user:link where further context for the event can be retrieved, in this case from the Facebook Graph API. Facebook started publishing Linked Data as RDF .
- The event links to a stream which is a URI where current events can be obtained in real-time by dereferencing the link.
- The namespace
event-processing.org is chosen as a generic home for this schema.
Conclusion
We are re-using and creating domain vocabularies to subclass the class Event. For example in the Facebook case we use the schema from the RDF/Turtle API provided by Facebook .
We developed this event model to satisfy requirements of an open platform where data from the Web can be re-used and which is extensible for open participation. Future updates to the event schema can be tracked on-line at .


")